統合開発環境:LiveCode 6プログラミング 初心者開発入門
無料オープンソース版「LiveCode Community Edition」の初級から中級のチュートリアルです。
このチュートリアルは、中学・高校生からプログラミングが始めての方達を対象にして、Mac&Winのアプリを同時に作ります。
LiveCode7 注:
LiveCode7 でのインターフェース開発は日本語も英文と同じ扱いができますが、日本語の外部書類保存はユニコードとしてバイナリーで保存しなくてはいけません。その他特殊な状況の場合、バージョン6の日本語の扱いが活かせることもあります。
21:フィールドにある日本語の扱い
この章の概略
スタックやフィールドのサイズは適当に広げてください。ライン09は空白です。念のため何行あるかメッセージ・ボックスから確かめてみます。
「13」と返されます。前章で行ったフィールド内の全ての文章を、他のフィールドに移すのはこのスクリプトでした。
これから文章の部分的な移し替えをやってみます。始めにライン1から2までを、フィールド2に移します。メッセージ・ボックスからでも、テンポのボタンを作って中に書いてでも良いです。ハンドラーの「mouseUp」は省略します。

ほとんどは、前章のすべてのテキストを移すスクリプトと同じですが、「line 1 to 2 of 」を加えて移すラインの範囲を明記しました。
次に今2行のラインが入っているフィールド「jp2」の後ろに、ライン3だけを置きます。

ライン3だけを取り出してテキストの最後に置くと、行替えがなされませんから、ユニエンコードした行替え「uniencode(cr)」を始めに付けて、フィールドの文の後ろ(after)に置きます。こうして改行も続けて1行に書く場合、改行(cr または return)やタブ(tab)等の記号は、必ずユニコード(UTF16)にしないと文字化けしますから注意してください。
ただし改行(cr または return)だけを、ユニコードのフィールドにスクリプトでプット(put)すると、フィールドは改行(cr または return)をユニコードとして扱います。この下の2行で書いたスクリプトは、上の1行で書いたスクリプトと同じ動作をします。
どういう事で、こういう仕様になっているのか些細な事ですが注意が必要です。
特定のキャラクターを指定して、テキスト・カラーを変えてみます。ライン3の9番目から11番目までのキャラクター「多襄丸」を赤文字にします。

この辺りは英語と同じ扱いです。テキスト・サイズやテキスト・ハイトも英語と同じに扱えます。ライン3の9番目から11番目までのキャラクター「多襄丸」を16ポイントにして、フィールド全体のテキスト・ハイト(行間)を20ポイントにします。

カット&ペーストも、英語と同じようにできます。ライン1(01)をカットして、ライン2(02)とライン3(03)の間にペーストします。

ライン1(01)をカットすると言う事は、最後に付いている改行(cr または return)も一緒にカットしていますから、ペーストする位置に改行を入れる必要はありません。「select before line 2 of fld "jp2"」で、ポジションにカーソルを入れて、ペーストします。ライン1(01)はカットされてない状態ですから、ここで使っている「line 2 of fld "jp2"」は「03」の事です。
日本語をクロスプラットフォームで保存する
何度も書いていますが、LiveCodeの日本語(ユニコード)は「UTF16」で表示します。始めに「UTF8」で保存する方法を書きます。次に「SJIS」です。「UTF16」は少し面倒な事柄を含んでいるので、最後に説明します。
英語のテキストは「url ("file:" &ファイル・パス) 」を使って保存しましたが、ユニコードはイメージと同じように、バイナリー・ファイルで保存します。基本形は以下の通りです。
基本はフィールドにある文字列をユニコードで取り出したら、ユニ・デコード(uniDecode)で「UTF8」に変換して、ファイル・パスにバイナリー(binfile)で保存します。しかしMacOSとWindowsでは改行の形式が違っているので、それを差し替えて保存しないと、Windowsのテキスト編集アプリで開いた時に、改行されない1行に繋がった文章になってしまいます。MacOSでは改行は、「cr」または「return」を使います。どちらも「ASCII 10」ですが、Windowsの改行は「crlf(ASCII 13)」を使います。
フィールド「jp1」の日本語を「UTF8」で保存します。「Cancel」された時のスクリプトは省略しています。
1)ファイルを保存する場所を得る「ask file」で、ファイル・パスを「it」に入れます。
2)フィールド「jp1」をユニコードで取り出して「jpUTF16」に入れます。
3)「jpUTF16」のすべてのユニコードの改行「cr(ASCII 10)」を、ユニコードの「crlf(ASCII 13)」に差し替えます。
4)バリアブル「jpUTF16」に入っている日本語文(UTF16)を、「uniDecode」で「ユニコードUTF8」に変換して、バリアブル「jpUtf8」に入れます。
5)バリアブル「jpUtf8」を、URL「binfile:」で「it」に入れてあるパスの場所のファイルに入れます。
これでMac OSのテキストエディットでも、Windowsのノートパッドでも開く事ができます。
日本語をSJISで保存する
最近はユニコードで保存する事がかなり一般的になっていますが、SJISで保存される事もまだかなりあるようです。LiveCodeではSJISを「Japanese」として扱います。
ほとんど「UTF8」と同じで、ユニ・デコード(uniDecode)を「UTF8」とするか、赤文字で書いた「Japanese」とするかの違いです。
「SJIS」は、単独のフラットフォーム用にファイル保存する場合は、バイナリーでなく「URL ("file:" & ファイル・パス)」で保存する事もできます。しかしファイルがどちらでも使えるように、バイナリーを使った方が良いでしょうね。
日本語のUTF8とSJISをインポートする
ファイルの保存は、ユニコード16を「UTF8」でユニ・デコード(uniDecode)しましたから、「UTF8」をLiveCodeにインポートするのは、バイナリーで受けたデータ(tUrl)を「UTF8」でユニ・エンコード(uniEncode)をします。「put "" into fld "jp2"」は、同じ内容のファイルをインポートするので、ファイルが入れ替わっている事を確認する為で、通常は必要ではありません。
「SJIS」の場合も全く同じで、ユニ・エンコード(uniEncode)を「SJIS(Japanese)」で行うだけの違いです。
BOMを付けたユニコードUTF16の保存
LiveCodeだけに限った事ではありませんが、「UTF16」を扱うにはちょっと単純でない問題があって、その事を少しお話してからにしましょう。
まずユニコードのファイルを作る場合、ファイルの先頭に「Byte Order Mark (BOM)」と言われるキャラクターコードを付けると言うのが、ユニコードの規格を決めている「ユニコードコンソーシアム」で決められています。これによって、プロセッサーの違い(MacOSかWindowsか)を判断できるようにします。と言っても、現在ではMacとWindowsのプロセッサーが同じになっているので、古いPowerPC用に作るファイルでなければ違いはなくなっているのですが、バイトオーダー・マーク(BOM)を付けると言う事だけは、そのままに残っています。
ユニコードは1文字がダブルバイト・キャラクターですから、普通の英数字(シングルバイト = 8ビット)を2文字合わせたメモリーで1文字(16ビット)を表示します。プロセッサーによってユニコード1文字に使うメモリーの組み合わせ方の順序が違っていて、その違いをビッグエンディアン、またはリトルエンディアンと言っています。つまりプロセッサーによる読み込み方の違いを、始めに「FEFF」と言う16進数で表した文字を、バイトオーダー・マーク(BOM)として付けておく事で、それをがどういう順序になっているか正しい読み込みの順序を判断させると言うものです。
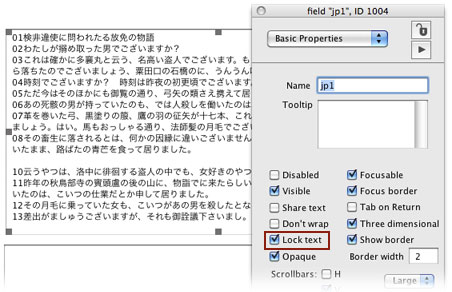
すべてのUTF16の文字には16進数の数字が振り当てられていて、LiveCodeのスクリプトの中にユニコード・キャラクターを使いたい時など、その数字からユニコードの文字に変換すると言う事もできます。サンプル・テキストのキャラクターを16進数と10進数に変換してみます。フィールド「jp1」をロック・テキスト(lockText)にしてください。
フィールド「jp1」には以下のスクリプトを入れます。
フィールド「jp1」のキャラクターをクリックすると、1行目にクリックした文字、その下に16進数で表したその文字の番号、その次の行には16進数を10進数にした数字が出ます。普通の英数字は、ASCIIと同じナンバーが10進数で出ます。「set the useUnicode to true」にすると、「charToNum」はユニコードのキャラクターを10進数に、「numToChar」は10進数をユニコードの文字に変換します。
「BOM」を作るのは、16進数の「FEFF」を10進数に変換して、その数字を「set the useUnicode to true」の状態で「numToChar」を使ってキャラクターに変換して、保存するユニコード・テキストの始めに付けます。
バイトオーダー・マーク(BOM)を付けないと、LiveCodeでない他のアプリで開いた場合、文字化けする事があります。しかしこれは「UTF16」で保存したファイルを他のアプリで開く場合で、LiveCodeで再び開く場合は「BOM」は付けても付けなくても、文字化けする事はありません。
インポートは、UTF16のファイルをUTF16で表示するので、極めてシンプルです。
この章で新しく出て来た言葉
useUnicode プロパティ(property)
set the useUnicode to true
put charToNum(the unicodeText of clickCharChunk()) into tDec
LiveCode7 でのインターフェース開発は日本語も英文と同じ扱いができますが、日本語の外部書類保存はユニコードとしてバイナリーで保存しなくてはいけません。その他特殊な状況の場合、バージョン6の日本語の扱いが活かせることもあります。
21:フィールドにある日本語の扱い
この章の概略- 日本語テキストを、ラインやキャラクター単位で移動
- 日本語テキストを、UFT8、SJISのプラットフォーム共通ファイルにして保存
- 日本語テキストを、バイトオーダーマークを付けたUTF16ファイルで保存
- コードの違う日本語ファイルを、LiveCodeのフィールドにインポート
- ユニコードの各文字に付けられた、16進数の表記について
日本語のラインやキャラクターの移動
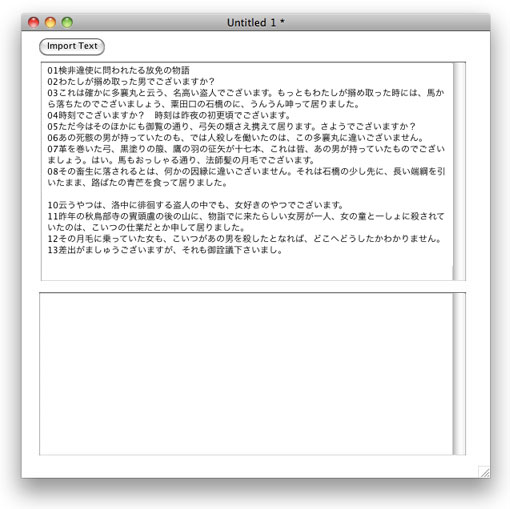
ニュー・メインスタックに、スクロール・フィールドを上下に2つ作って、上のフィールドの名前(name)は「jp1」、下のフィールドは「jp2」にしてください。文字列のライン・ナンバーが分かりやすいように、番号を振ったテキストをウェブに用意しました。芥川龍之介の薮の中の一部を「UTF8」で保存したテキスト・ファイルです。フィールド「jp1」にインポートしてください。「Import Text」と言うボタンにon mouseUp get url "http://kenjikojima.com/livecode/download/yabunonaka.txt" put unicode uniEncode(it,utf8) into fld "jp1" end mouseUp
スタックやフィールドのサイズは適当に広げてください。ライン09は空白です。念のため何行あるかメッセージ・ボックスから確かめてみます。
put the num of lines of fld "jp1"
「13」と返されます。前章で行ったフィールド内の全ての文章を、他のフィールドに移すのはこのスクリプトでした。
put unicode the unicodeText of fld "jp1" into fld "jp2"
これから文章の部分的な移し替えをやってみます。始めにライン1から2までを、フィールド2に移します。メッセージ・ボックスからでも、テンポのボタンを作って中に書いてでも良いです。ハンドラーの「mouseUp」は省略します。
put unicode the unicodeText of line 1 to 2 of fld "jp1" into fld "jp2"
ほとんどは、前章のすべてのテキストを移すスクリプトと同じですが、「line 1 to 2 of 」を加えて移すラインの範囲を明記しました。
次に今2行のラインが入っているフィールド「jp2」の後ろに、ライン3だけを置きます。
put unicode uniencode(cr) & \
the unicodeText of line 3 of fld "jp1" after fld "jp2"
ライン3だけを取り出してテキストの最後に置くと、行替えがなされませんから、ユニエンコードした行替え「uniencode(cr)」を始めに付けて、フィールドの文の後ろ(after)に置きます。こうして改行も続けて1行に書く場合、改行(cr または return)やタブ(tab)等の記号は、必ずユニコード(UTF16)にしないと文字化けしますから注意してください。
ただし改行(cr または return)だけを、ユニコードのフィールドにスクリプトでプット(put)すると、フィールドは改行(cr または return)をユニコードとして扱います。この下の2行で書いたスクリプトは、上の1行で書いたスクリプトと同じ動作をします。
put cr after fld "jp2" put unicode the unicodeText of line 3 of fld "jp1" after fld "jp2"
どういう事で、こういう仕様になっているのか些細な事ですが注意が必要です。
特定のキャラクターを指定して、テキスト・カラーを変えてみます。ライン3の9番目から11番目までのキャラクター「多襄丸」を赤文字にします。
set the textColor of char 9 to 11 of line 3 of fld "jp2" to red
この辺りは英語と同じ扱いです。テキスト・サイズやテキスト・ハイトも英語と同じに扱えます。ライン3の9番目から11番目までのキャラクター「多襄丸」を16ポイントにして、フィールド全体のテキスト・ハイト(行間)を20ポイントにします。
set the textSize of char 9 to 11 of line 3 of fld "jp2" to 16 set the textHeight of fld "jp2" to 20
カット&ペーストも、英語と同じようにできます。ライン1(01)をカットして、ライン2(02)とライン3(03)の間にペーストします。
cut line 1 of fld "jp2" select before line 2 of fld "jp2" paste
ライン1(01)をカットすると言う事は、最後に付いている改行(cr または return)も一緒にカットしていますから、ペーストする位置に改行を入れる必要はありません。「select before line 2 of fld "jp2"」で、ポジションにカーソルを入れて、ペーストします。ライン1(01)はカットされてない状態ですから、ここで使っている「line 2 of fld "jp2"」は「03」の事です。
日本語をクロスプラットフォームで保存する
始めはUFT8です
何度も書いていますが、LiveCodeの日本語(ユニコード)は「UTF16」で表示します。始めに「UTF8」で保存する方法を書きます。次に「SJIS」です。「UTF16」は少し面倒な事柄を含んでいるので、最後に説明します。
英語のテキストは「url ("file:" &ファイル・パス) 」を使って保存しましたが、ユニコードはイメージと同じように、バイナリー・ファイルで保存します。基本形は以下の通りです。
put uniDecode(the unicodeText of fld フィールド名, utf8) \
into url ("binfile:" & ファイル・パス)
基本はフィールドにある文字列をユニコードで取り出したら、ユニ・デコード(uniDecode)で「UTF8」に変換して、ファイル・パスにバイナリー(binfile)で保存します。しかしMacOSとWindowsでは改行の形式が違っているので、それを差し替えて保存しないと、Windowsのテキスト編集アプリで開いた時に、改行されない1行に繋がった文章になってしまいます。MacOSでは改行は、「cr」または「return」を使います。どちらも「ASCII 10」ですが、Windowsの改行は「crlf(ASCII 13)」を使います。
フィールド「jp1」の日本語を「UTF8」で保存します。「Cancel」された時のスクリプトは省略しています。
ask file "Save UTF8 File:" with "jpUtf8.txt"
put the unicodeText of fld "jp1" into jpUTF16
replace uniEncode(cr) with uniEncode(crlf) in jpUTF16
put uniDecode(jpUTF16, utf8) into jpUtf8
put jpUtf8 into URL ("binfile:" & it)
1)ファイルを保存する場所を得る「ask file」で、ファイル・パスを「it」に入れます。
2)フィールド「jp1」をユニコードで取り出して「jpUTF16」に入れます。
3)「jpUTF16」のすべてのユニコードの改行「cr(ASCII 10)」を、ユニコードの「crlf(ASCII 13)」に差し替えます。
4)バリアブル「jpUTF16」に入っている日本語文(UTF16)を、「uniDecode」で「ユニコードUTF8」に変換して、バリアブル「jpUtf8」に入れます。
5)バリアブル「jpUtf8」を、URL「binfile:」で「it」に入れてあるパスの場所のファイルに入れます。
これでMac OSのテキストエディットでも、Windowsのノートパッドでも開く事ができます。
日本語をSJISで保存する
最近はユニコードで保存する事がかなり一般的になっていますが、SJISで保存される事もまだかなりあるようです。LiveCodeではSJISを「Japanese」として扱います。
ask file "Save SJIS File:" with "jpSJIS.txt"
put the unicodeText of fld "jp1" into jpUTF16
replace uniencode(cr) with uniencode(crlf) in jpUTF16
put uniDecode(jpUTF16, japanese) into jpSJIS
put jpSJIS into URL ("binfile:" & it)
ほとんど「UTF8」と同じで、ユニ・デコード(uniDecode)を「UTF8」とするか、赤文字で書いた「Japanese」とするかの違いです。
「SJIS」は、単独のフラットフォーム用にファイル保存する場合は、バイナリーでなく「URL ("file:" & ファイル・パス)」で保存する事もできます。しかしファイルがどちらでも使えるように、バイナリーを使った方が良いでしょうね。
日本語のUTF8とSJISをインポートする
ファイルの保存は、ユニコード16を「UTF8」でユニ・デコード(uniDecode)しましたから、「UTF8」をLiveCodeにインポートするのは、バイナリーで受けたデータ(tUrl)を「UTF8」でユニ・エンコード(uniEncode)をします。「put "" into fld "jp2"」は、同じ内容のファイルをインポートするので、ファイルが入れ替わっている事を確認する為で、通常は必要ではありません。
put "" into fld "jp2" -- 通常は必要ありません
answer file "Select UTF8 File:"
put url ("binfile:" & it) into tUrl
put unicode uniEncode(tUrl, utf8) into fld 2
「SJIS」の場合も全く同じで、ユニ・エンコード(uniEncode)を「SJIS(Japanese)」で行うだけの違いです。
put "" into fld "jp2" -- 通常は必要ありません
answer file "Select UTF8 File:"
put url ("binfile:" & it) into tUrl
put unicode uniEncode(tUrl, japanese) into fld 2
BOMを付けたユニコードUTF16の保存
LiveCodeだけに限った事ではありませんが、「UTF16」を扱うにはちょっと単純でない問題があって、その事を少しお話してからにしましょう。
まずユニコードのファイルを作る場合、ファイルの先頭に「Byte Order Mark (BOM)」と言われるキャラクターコードを付けると言うのが、ユニコードの規格を決めている「ユニコードコンソーシアム」で決められています。これによって、プロセッサーの違い(MacOSかWindowsか)を判断できるようにします。と言っても、現在ではMacとWindowsのプロセッサーが同じになっているので、古いPowerPC用に作るファイルでなければ違いはなくなっているのですが、バイトオーダー・マーク(BOM)を付けると言う事だけは、そのままに残っています。
ユニコードは1文字がダブルバイト・キャラクターですから、普通の英数字(シングルバイト = 8ビット)を2文字合わせたメモリーで1文字(16ビット)を表示します。プロセッサーによってユニコード1文字に使うメモリーの組み合わせ方の順序が違っていて、その違いをビッグエンディアン、またはリトルエンディアンと言っています。つまりプロセッサーによる読み込み方の違いを、始めに「FEFF」と言う16進数で表した文字を、バイトオーダー・マーク(BOM)として付けておく事で、それをがどういう順序になっているか正しい読み込みの順序を判断させると言うものです。
すべてのUTF16の文字には16進数の数字が振り当てられていて、LiveCodeのスクリプトの中にユニコード・キャラクターを使いたい時など、その数字からユニコードの文字に変換すると言う事もできます。サンプル・テキストのキャラクターを16進数と10進数に変換してみます。フィールド「jp1」をロック・テキスト(lockText)にしてください。
フィールド「jp1」には以下のスクリプトを入れます。
on mouseUp
if clickCharChunk() is empty then exit to top
put unicode the unicodeText of clickCharChunk() & \
uniEncode(cr) into fld "jp2"
set the useUnicode to true --「charToNum」でユニコードの番号を得る
put charToNum(the unicodeText of clickCharChunk()) into tDec
put "UnicodeHex: "& BaseConvert(tDec,10,16) & \
uniencode(cr) & "UnicodeDecimal: "&tDec after fld "jp2"
end mouseUp
フィールド「jp1」のキャラクターをクリックすると、1行目にクリックした文字、その下に16進数で表したその文字の番号、その次の行には16進数を10進数にした数字が出ます。普通の英数字は、ASCIIと同じナンバーが10進数で出ます。「set the useUnicode to true」にすると、「charToNum」はユニコードのキャラクターを10進数に、「numToChar」は10進数をユニコードの文字に変換します。
「BOM」を作るのは、16進数の「FEFF」を10進数に変換して、その数字を「set the useUnicode to true」の状態で「numToChar」を使ってキャラクターに変換して、保存するユニコード・テキストの始めに付けます。
set the useUnicode to true
put numToChar(baseConvert("FEFF",16,10)) into tBom
ask file "Save UTF16 File:" with "jpBomUtf16.txt"
put the unicodeText of fld "jp1" into jpUTF16
replace uniencode(cr) with uniencode(crlf) in jpUTF16
put tBom & jpUTF16 into URL ("binfile:" & it)
バイトオーダー・マーク(BOM)を付けないと、LiveCodeでない他のアプリで開いた場合、文字化けする事があります。しかしこれは「UTF16」で保存したファイルを他のアプリで開く場合で、LiveCodeで再び開く場合は「BOM」は付けても付けなくても、文字化けする事はありません。
インポートは、UTF16のファイルをUTF16で表示するので、極めてシンプルです。
put "" into fld "jp2" -- 通常は必要ありません
answer file "Select UTF16 File:"
put url("binfile:" & it) into tUrl
put unicode tUrl into fld "jp2"
この章で新しく出て来た言葉
useUnicode プロパティ(property)
numToChar, charToNum を実行させる際ダブルバイト・キャラクターとして認識させる
set the useUnicode to trueput charToNum(the unicodeText of clickCharChunk()) into tDec